
Lesen kostet Zeit. In einer Welt, in der es ein Überangebot an Informationen gibt, sind Zusammenfassungen von Informationen wünschenswert. Eine der anspruchsvollsten Aufgaben im Bereich der natürlichen Sprachverarbeitung (Natural Language Processing, NLP), ist das automatische Zusammenfassen von Textdaten, die Automatic Text Summarization (ATS). Eine automatische Zusammenfassung sollte hierbei den Inhalt eines Textes komprimiert wiedergeben, wobei wichtige Aspekte beibehalten und unwichtige Details verworfen werden. Hierbei unterscheidet man zwischen zwei grundsätzlichen Ansätzen.
Extractive Summarization
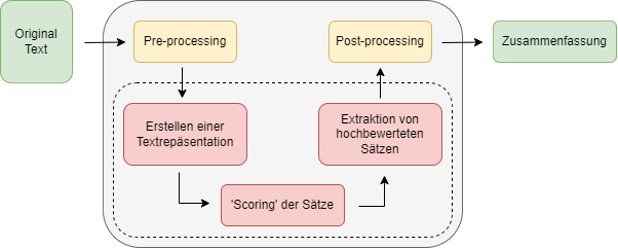
Stellen Sie sich vor, Sie würden in einem Text die wichtigsten Sätze mit einem Textmarker hervorheben, diese dann entnehmen (extrahieren) und in einem neuen Dokument zusammenfügen. Genau das ist die Idee bei der „Extractive Summarization“. In Darstellung 1 ist die Architektur eines solchen Systems aufgezeigt. Die Erstellung einer Zusammenfassung funktioniert hierbei folgendermaßen:
- Pre-processing: Wie vor den meisten Aufgaben der natürlichen Sprachverarbeitung wird der Text zuerst in eine geordnete Form gebracht. Dieses „Pre-processing“ beinhaltet beispielsweise die Aufteilung des Textes in einzelne Wörter (Tokenisierung), sowie die Überführung aller Wörter in ihre Grundform (Lemmatisierung). Dies dient dazu, dass beispielsweise die Wortformen „Text“ und „Textes“ als identisch erkannt werden.
- Erstellen einer textuellen Repräsentation: Anschließend wird der Text in eine geeignete Repräsentation überführt. Eine beispielhafte Vorgehensweise ist, die Sätze als „bag-of-words“ darzustellen, d.h. als eine Aufzählung der in dem Satz vorkommenden Wörter mit der Anzahl ihres Auftretens, ohne Beachtung der Reihenfolge.
- „Scoring“ der Sätze: Das Herzstück eines „Extractive Summarization“-Systems ist die Beurteilung darüber, welche der Sätze eines Textes wichtig bzw. aussagekräftig, und welche weniger wichtig sind. Hierbei gibt es viele verschiedene Methoden, die Sätze in eine Reihenfolge zu bringen. Beispielhaft zu nennen sind statistische Methoden, bei denen wichtige Sätze und Wörter aus dem Ausgangstext auf der Grundlage der statistischen Analyse einer Reihe von Merkmalen extrahiert werden. Der „wichtigste“ Satz könnte beispielsweise als derjenige definiert werden, welcher am häufigsten vorkommt. Da dieses Aussuchen der wichtigsten Sätze eng mit der Informationsextraktion verwandt ist, möchte ich den interessierten Leser an dieser Stelle auf einen Artikel über dieses Thema verweisen.
- Extraktion von hoch bewerteten Sätzen: Nach der Sortierung der Sätze muss nun noch entschieden werden, welche und wie viele Sätze aus dem Originaltext zur Erstellung der Zusammenfassung verkettet werden. Oft wird die Anzahl der Sätze durch eine vorher gewählte Komprimierungsrate bestimmt, mit der die gewünschte Länge der Zusammenfassung im Vergleich zur Länge des Originaltextes bezeichnet wird. Typischerweise wird die Reihenfolge der ausgewählten Sätze entsprechend des Eingabetextes beibehalten.
- Post-Processing: In einem letzten Schritt kann der zusammengesetzte Text nochmal überarbeitet werden. Beispielweise durch die Neuordnung der extrahierten Sätze, oder durch das Ersetzen von Pronomen durch Eigennamen. Hierbei wird beispielsweise der Satz „Er isst einen Apfel“ nach „Peter isst einen Apfel“ überführt, weil ersteres durch das Wegfallen von Zwischensätzen unverständlich geworden sein könnte und die Referenz des Pronomens nicht mehr klar ersichtlich ist.
„Extractive Summarization“ ist eine relativ einfache Herangehensweise, die typischerweise für hohe Präzision sorgt. Allerdings ist der fehlende Zusammenhang zwischen den einzelnen Sätzen oftmals ein Problem. Außerdem ist es fast unmöglich, eine starke Kompression des Textes zu erzielen, um zum Beispiel ein Buch in wenigen Sätzen zusammenfassen. Ungeeignet ist diese Herangehensweise außerdem für Texte, die viel Interpretation benötigen.
Abstractive Summarization
Eine andere Herangehensweise besteht darin, den Originaltext zuerst in eine, typischerweise nicht textuelle, Zwischen-Repräsentation zu überführen, die die Semantik des Textes enkodiert. Aus dieser wird dann die Zusammenfassung erstellt, indem völlig neue Sätze generiert werden. Ein Beispiel für eine hochkomprimierte, abstraktive Zusammenfassung des Stückes „Romeo und Julia“ von Shakespeare könnte Folgende sein: „Mädchen und Junge verlieben sich. Familien hassen sich. Viel Drama und beide sterben.“2. Diese Herangehensweise kann im Idealfall hochqualitative Zusammenfassungen generieren, die menschengemachten Zusammenfassungen sehr ähnlich sind. Allerdings ist die technische Umsetzung hochanspruchsvoll, da die Maschine (a) den Inhalt und die wichtigsten Konzepte eines Textes erfassen muss, und (b) neue Sätze generieren muss, um den Inhalt zu paraphrasieren.
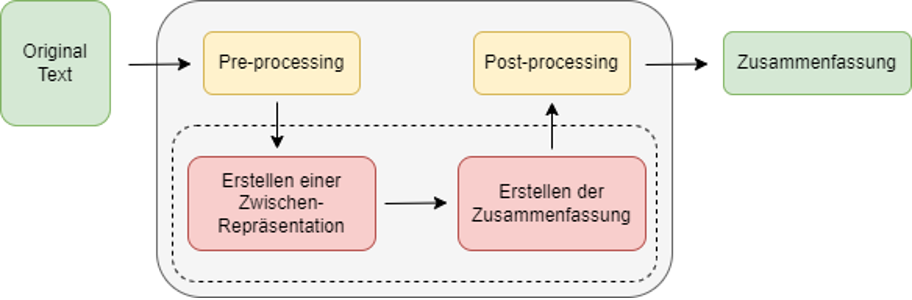
Wie bei den meisten anspruchsvollen Aufgaben in der natürlichen Sprachverarbeitung wird „Abstractive Summarization“ heutzutage praktisch ausschließlich durch neuronale Netze und bestimmte Deep-Learning-Architekturen umgesetzt. In Darstellung 2 ist die Architektur eines solchen Systems aufgezeigt, wobei die Erstellung einer Zusammenfassung folgendermaßen abläuft:
- Erstellen einer Zwischenrepräsentation: Im ersten Schritt nach dem Pre-processing (s.o.) wird der Originaltext in eine Zwischenrepräsentation überführt, mit dem Ziel den Inhalt des Textes zu erfassen. Hierzu werden vortrainierte Sprachmodelle, zum Beispiel BERT3, verwendet, die die Wörter des Originaltextes in sogenannte kontextualisierte, kontinuierliche Wordrepräsentationen oder Worteinbettungen, übersetzen. Die Idee hierbei ist, Wörter als hochdimensionale Vektoren darzustellen, wobei semantisch ähnlichen Wörtern auch ähnliche Vektoren zugewiesen werden. Somit kann man von dem Abstand zwischen zwei Worteinbettungen auf die semantische Beziehung zwischen den zugehörigen Wörtern schließen. Die Bedeutung eines Wortes lässt sich also durch algebraische Operationen erschließen, was auch Maschinen möglich ist.
- Erstellen der Zusammenfassung: Die Zwischen-Repräsentation des Textes wird anschließend in ein neuronales Netz gegeben. Dieses wurde zuvor mithilfe großer Mengen manuell erstellter Paare aus Originaltext und Zusammenfassung darauf trainiert, passende Zusammenfassungen in natürlicher Sprache zu generieren. Die Länge und der Stil der automatisch generierten Zusammenfassung ist hierbei eine direkte Konsequenz der zuvor verwendeten Trainingsdaten. Auch die Qualität des Modells wird neben der Auswahl einer passenden Architektur primär durch die Qualität und Quantität der Trainingsdaten bestimmt. Dies beruht darauf, dass Systeme zur automatischen Textzusammenfassung wie alle neuronalen Netze keinerlei kreative Fähigkeiten entwickeln, sondern lediglich ein direktes Produkt ihrer Erfahrungen sind.
Mithilfe von „Abstractive Summarization“ lassen sich komprimierte, paraphrasierte Zusammenfassungen erstellen, die näher an manuellen, menschgemachten Zusammenfassungen liegen. Außerdem ist durch die Generierung neuer Sätze eine stärkere Komprimierung als bei extraktiven Methoden möglich. Allerdings ist die Erstellung einer qualitativ hochwertigen abstrakten Zusammenfassung aufgrund der benötigten Technologien (noch) sehr schwierig4.
Hybride Ansätze
Natürlich können beide Ansätze auch zu hybriden Ansätzen der automatischen Textzusammenfassung kombiniert werden. Hierbei wird typischerweise mithilfe von „Extractive Summarization“ in einem ersten Schritt der Umfang des Textes reduziert, bevor dann Methoden der „Abstractive Summarization“ angewendet werden.
Ausreifung der Technologie
In einem Überblicksartikel zu der Technologie aus dem Jahre 2021 stellen die Autoren fest, dass „die generierten Zusammenfassungen trotz aller entwickelten Methoden immer noch weit von Menschen erzeugten Zusammenfassungen entfernt sind“1. Trotzdem gibt es bereits viele vielversprechende Ansätze und erfolgversprechende Ergebnisse. Eines der neusten dieser vielversprechenden Modelle ist BertSum.
Anwendung in der Industrie
Textzusammenfassungs-Methoden können im Prinzip überall dort verwendet werden, wo Informationen in Form von Prosatexten vorliegen, z.B. News, Berichte, Dokumentationen, Wissensquellen, Marktanalysen und Personalmanagement (Auswahl von Bewerbern aus einem großen Pool o.ä.).
Quellenverzeichnis
1. Wafaa S. El-Kassas, Cherif R. Salama, Ahmed A. Rafea, and Hoda K. Mohamed. “Automatic text summarization: A comprehensive survey”. Expert Systems with Applications, Volume 165 (2021).
2. https://learnattack.de/journal/zusammenfassung-von-romeo-und-julia/
3. Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
4. Hou, L., Hu, P., & Bei, C. (2017). Abstractive Document Summarization via Neural Model with Joint Attention. Paper presented at the Natural Language Processing and Chinese Computing, Dalian, China.
Tanja Bäumel ist Computerlinguistik-Forscherin mit einem multidisziplinären Hintergrund in Computerlinguistik, Informatik und Kognitionswissenschaft, aktuell im Forschungsbereich „Multilingualität und Sprachtechnologie“ am Deutschen Forschungszentrum für Künstliche Intelligenz. Sie forscht auf dem Gebiet der erklärbaren künstlichen Intelligenz (XAI), mit Schwerpunkt auf der Interpretierbarkeit groß angelegter vortrainierter Sprachmodelle.






