
Beschreibung der KI Technologie/Methode
Inwiefern sind Daten wertvoll?
Die weltweite Datenmenge nimmt seit Jahren exponentiell zu. Von dieser Fülle an Daten profitieren vor allem Unternehmen: Ihre Effizienz und Innovation schnellen in die Höhe – eine Entwicklung, die sich in absehbarer Zeit noch weiter verstärken wird.
„Daten sind das neue Öl“ ist ein populärer Ausschnitt eines Zitats, welches vermutlich vom britischen Mathematiker Clive Humby stammt.1 Ähnlich wie Rohöl werden Rohdaten auch erst dann wirklich wertvoll, wenn sie raffiniert, beziehungsweise aufbereitet werden. Erst wenn sie eine für den Anwendungsfall nutzbare Form haben, können aus ihnen beispielsweise Handlungsempfehlungen abgeleitet werden.2
Folgende Aussage vom ehemaligen Vizepräsidenten des Marktforschungs- und Beratungsunternehmen Gartner, Peter Sondergaard, ist sehr treffend:
Insbesondere beim Maschinellen Lernen (ML), welches einen wichtigen Teilbereich der KI darstellt, spricht man von selbstlernenden Algorithmen und einen datengetriebenen Ansatz. Gerade die Auswahl der richtigen Daten, in geeigneter Qualität und erforderlicher Quantität ist Grundvoraussetzung für die Trainingsphase eines KI-Systems und damit für das Gelingen eines KI-Projektes.
Machine Learning ist ein Teilbereich der künstlichen Intelligenz und nutzt Algorithmen und statistische Methoden, um Daten zu analysieren und Muster zu erkennen.
Warum ist eine gute Datenverarbeitung so wichtig?
Ähnlich wie die Unterlagen eines Schülers korrekt und vollständig sein müssen, damit er für eine Klassenarbeit erfolgreich lernen kann, müssen auch die Trainingsdaten für den Erfolg eines KI-Projekts qualitative und quantitative Anforderungen erfüllen. Konkret werden unter anderem folgende Anforderungen an die Daten gestellt3:
- Vollständigkeit
- Widerspruchsfreiheit
- Konsistenz
- Aktualität
Wenn jedoch die Qualität der Eingabedaten schon unzureichend ist, liefert die Ausgabe des KI-Modells höchstwahrscheinlich nicht die gewünschten Ergebnisse („Garbage in, garbage out“). Neben der Datenqualität ist auch die Datenmenge für den Erfolg eines KI-Projekts von zentraler Bedeutung. Im Allgemeinen steigt die Genauigkeit eines KI-Modells je mehr Daten in hinreichender Qualität zur Verfügung stehen.
Wie funktioniert die Datenaufbereitung in der Praxis?
In der Regel sind mehrere Arbeitsschritte notwendig, damit Rohdaten zur Entwicklung und Anwendung KI-basierter Technologien eingesetzt werden können. Am Beispiel der Nutzung von Kundendaten in einem Unternehmen des produzierenden Gewerbes zur Vorhersage des zukünftigen Kaufverhaltens eines Kunden kann dies verdeutlicht werden.
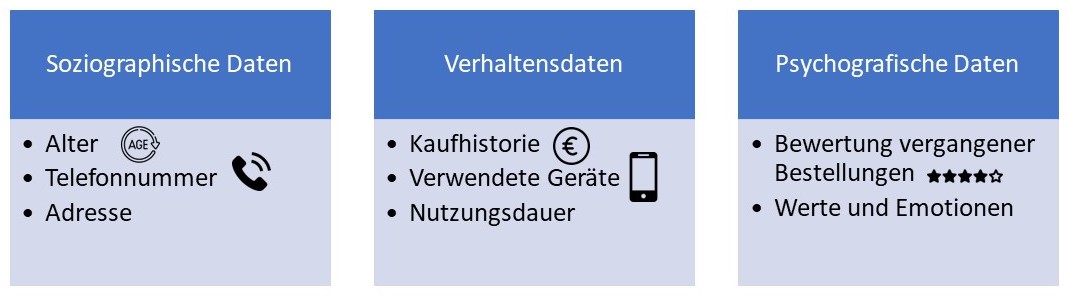
- Datenerfassung: In einem ersten Schritt müssen sämtliche Kundendaten erfasst werden, die für den Anwendungsfall relevant sind. Wie in Abbildung 1 dargestellt, können dies bei einem Privatkunden zum Beispiel soziodemographische Daten wie seine Adresse, Telefonnummer und Geburtsdatum, Verhaltensdaten wie die Kaufhistorie und die genutzten Geräte sowie psychografische Daten wie die Bewertung vergangener Bestellungen sein.4 Herausfordernd wird die Datenerfassung dadurch, dass die benötigten Daten oft aus verschiedenen Subsystemen mit unterschiedlichen Datenformaten zusammengeführt werden müssen. Zudem liegen sie anfangs meist in unstrukturierter Form vor.
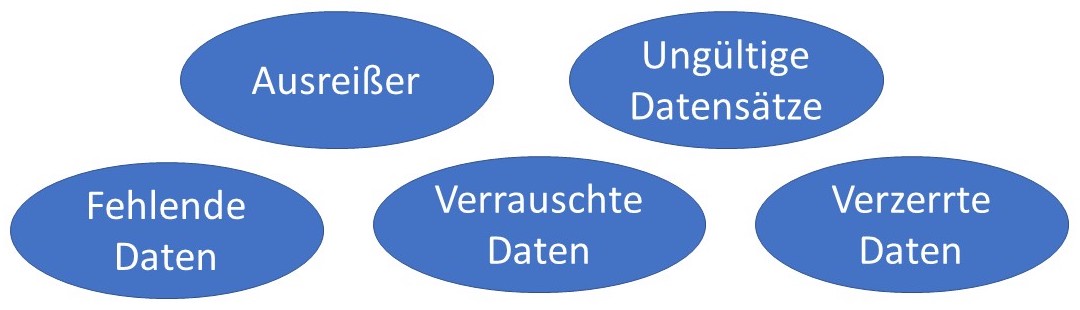
- Datenbereinigung: Für den Erfolg der Anwendung sind auch die Vollständigkeit und Vergleichbarkeit der Daten von zentraler Bedeutung. Deshalb empfiehlt es sich zuerst, Einträge aus den Datensätzen zu entfernen, welche für den späteren Anwendungsfall irrelevant sind. Oftmals ist es auch notwendig, fehlende Daten zu ergänzen, da zum Beispiel zu einem bestimmten Kunden keine Anschrift hinterlegt ist. Zudem können fehlerhafte Einträge wie ungültige Postleitzahlen oder Datenduplikate (mehrfache Registrierung des Kunden) vorliegen, die korrigiert beziehungsweise entfernt werden müssen. Damit die Daten später verarbeitet werden können, müssen diese in einen einheitlichen Datentyp konvertiert werden. Abbildung 2 illustriert mögliche Fehler in den Daten, die bereinigt werden müssen. Abschließend ist eine Standardisierung der Daten erforderlich, damit sie vergleichbar sind und vom KI-Modell verarbeitet werden können. Beispielsweise können sie so transformiert werden, dass alle Datenausprägungen Werte zwischen null und eins annehmen.
- Datenexploration: Nach der Datenbereinigung erfolgt die explorative Datenanalyse. Um Unstimmigkeiten und Muster in den Daten zu erkennen, bietet sich eine Visualisierung der Daten an. Gängige Methoden sind die Erstellung von Histogrammen, Box-Plots oder Streuungsdiagrammen. Die Datenvisualisierung erleichtert zudem den Austausch mit Mitarbeitern aus IT-fernen Fachabteilungen. Im Zuge der Datenexploration ist es zum Beispiel möglich, das Kaufverhalten von Kunden ähnlichen Alters zu vergleichen oder Kunden mit ungewöhnlich hohen Bestellmengen (Ausreißer) zu detektieren.
- Merkmalsextraktion: Abschließend werden aus den aufbereiteten Daten bestimmte Merkmale extrahiert, welche als Eingangsgröße für das KI-Modell verwendet werden können. Mögliche Merkmale können das Alter des Kunden, Bestellhäufigkeit, Bestellmenge, Bestellwert oder Surfverhalten sein. Diese können genutzt werden, um beispielsweise den nächsten Bestellzeitpunkt und die Bestellmenge eines Kunden vorherzusagen.
Mögliche Anwendungsbereiche
Die Einsatzmöglichkeiten für Daten bzw. intelligente Datenverarbeitung sind nahezu unbegrenzt und umfassen praktisch alle Branchen (insbesondere IT, Dienstleistungen, Finance, Retail) und auch alle Unternehmensbereiche, in denen entsprechende Daten, die zur Analyse geeignet sind, vorliegen, wie z.B. Logistik, Produktion, Supply Chain, Beschaffung/Einkauf, Personalwesen, Kundenmanagement, Marketing und Vertrieb, Qualitätskontrolle / Qualitätssicherung.6
Nutzen und Voraussetzungen für KMU
Der Nutzen für KMU liegt vor allem in der Automatisierung und entsprechenden Effizienzgewinnen. AutoML-Tools, die Aufgaben bei der Entwicklung und Bereitstellung von ML-Modellen automatisieren, stellen sowohl für Datenspezialisten als auch Datenanalysten einen entscheidenden Durchbruch dar, da Datennutzer mit diesen Tools Teile des ML-Workflows, z. B. Datenaufbereitung, Training und Auswahl des Modells und vieles mehr, automatisieren können. Einsparungen ergeben sich also nicht nur durch die Analyse, sondern auch dadurch, dass aufwändige Arbeiten (Laden, Auswählen, Aufbereiten und Bereinigen von Daten), die bisher bis zu 80 % der Arbeitszeit beanspruchten, nur noch etwa 45 % der Zeit benötigen, wie eine von Anaconda durchgeführte und von Datanami veröffentlichte Befragung unter Datenspezialisten ergab.7 Dies lässt mehr Zeit für die Analyse. Menschliche Fehler, die bei manuellen Modellierungsprozessen auftreten, werden ebenfalls reduziert, was die Genauigkeit erhöht.
Einsparungen können jedoch auch dadurch entstehen, dass wenig genutzte Firmendaten besser verwaltet werden. Studien der Analysten von IDC8 zeigen, dass ca. 60-90% aller Firmendaten – ein exorbitant hoher Prozentsatz – kalte Daten sind. Also Daten, die nicht oder nur selten genutzt werden. Diese Daten können mittels intelligenter Datenmanagement-Software identifiziert und geräuschlos auf günstige Speicher transferiert werden. So lassen sich Kosten für teure Speicher einsparen und gleichzeitig ein transparenter Überblick über den aktuellen Datenbestand erzeugen. Auch Analysen über Dateitypen, automatische Archivierungen und vieles mehr sind möglich.
Eine notwendige Voraussetzung für den Einsatz von Business Intelligence-Technologien ist die Sammlung von unstrukturierten Massendaten (Big Data) als Grundlage für darauf aufbauende, komplexe statistische Auswertungen (Business Analytics). Wie auch bei anderen KI-Technologien kommt hier der Qualität der Daten eine entscheidende Bedeutung zu. Im Hinblick auf das Personal müssen Controller sich aktiv mit Big Data auseinander setzen bzw. auseinander setzen können.
Weiterführende Informationen
- Reifegrad: Auswahl aus weitegehend noch Teil von Forschungsprojekten, bereits erste marktreife Produkte vorhanden, wird als Standard in ausgewählten Einsatzbereichen eingesetzt und/oder es existieren vielfältige Anbieter für die Technologie
- Beispiel-Anwendungen: Überblick & Verlinkung zu den Beispiel-Anwendungen (im KIWW-Wissenspool sowie extern)
- Forscher:innen und Anbieter: Überblick & Verlinkung zu den Forscher:innen und Anbietern
Quellenverzeichnis
1. Arthur, C. (2013). Tech giants may be huge, but nothing matches big data.
2. Stal, M. (2017). Data is the new Oil [Clive Humby] JavaSpektrum, (1), 3.
3. Keim, D. und Sattler, K. W. (2020). Von Daten zu KI –Intelligentes Datenmanagement als Basis für Data Science und den Einsatz Lernender Systeme [Whitepaper]. Plattform Lernende Systeme.
4. https://www.crossengage.io/de/kundendaten-ein-ueberblick/
5. o. A. (2020). Kundendaten: ein Überblick.
6. Gadatsch, A. (2017): “Big Data – Datenanalyse als Eintrittskarte in die Zukunft”, in Big Data für Entscheider, pp. 1-10.
7. https://www.datanami.com/2021/07/27/anacondas-2021-state-of-data-science-report-highlights-support-for-open-source-impacts-from-covid-19/
8. https://www.idc.com/search/simple/perform_.do?sortBy=DATE&query=&srchIn=ALLRESEARCH&src=&athrT=10&hitsPerPage=25&lang=English&cmpT=10&top=4_545
Dieser Beitrag wurde von Manuel A. Heid verfasst. Er ist Researcher am Deutschen Forschungszentrum für Künstliche Intelligenz (DFKI) und hat sich im Projekt Mittelstand-Digitalzentrum mit der Einführung KI-basierter Lösungen in Unternehmen beschäftigt sowie KMU auf dem Weg zum Einsatz dieser Lösungen im Bereich der optischen Qualitätskontrolle unterstützt.






